创建数据复制任务
数据复制功能可以帮助您实现同/异构数据源间的实时同步,适用于数据迁移/同步、数据灾备、读性能扩展等多种业务场景。本文介绍数据复制功能的具体使用流程,帮助您快速掌握如何创建、监控和管理数据复制任务。
前提条件
在创建数据复制任务前,您需要执行下述准备工作:
操作步骤
本文以 MySQL 实时同步至 MongoDB 为例,为您演示数据复制任务的创建流程,其他数据源也可参考此流程。
登录 Tapdata Cloud 平台。
在左侧导航栏,单击数据复制。
单击页面右侧的创建,跳转到任务配置页面。
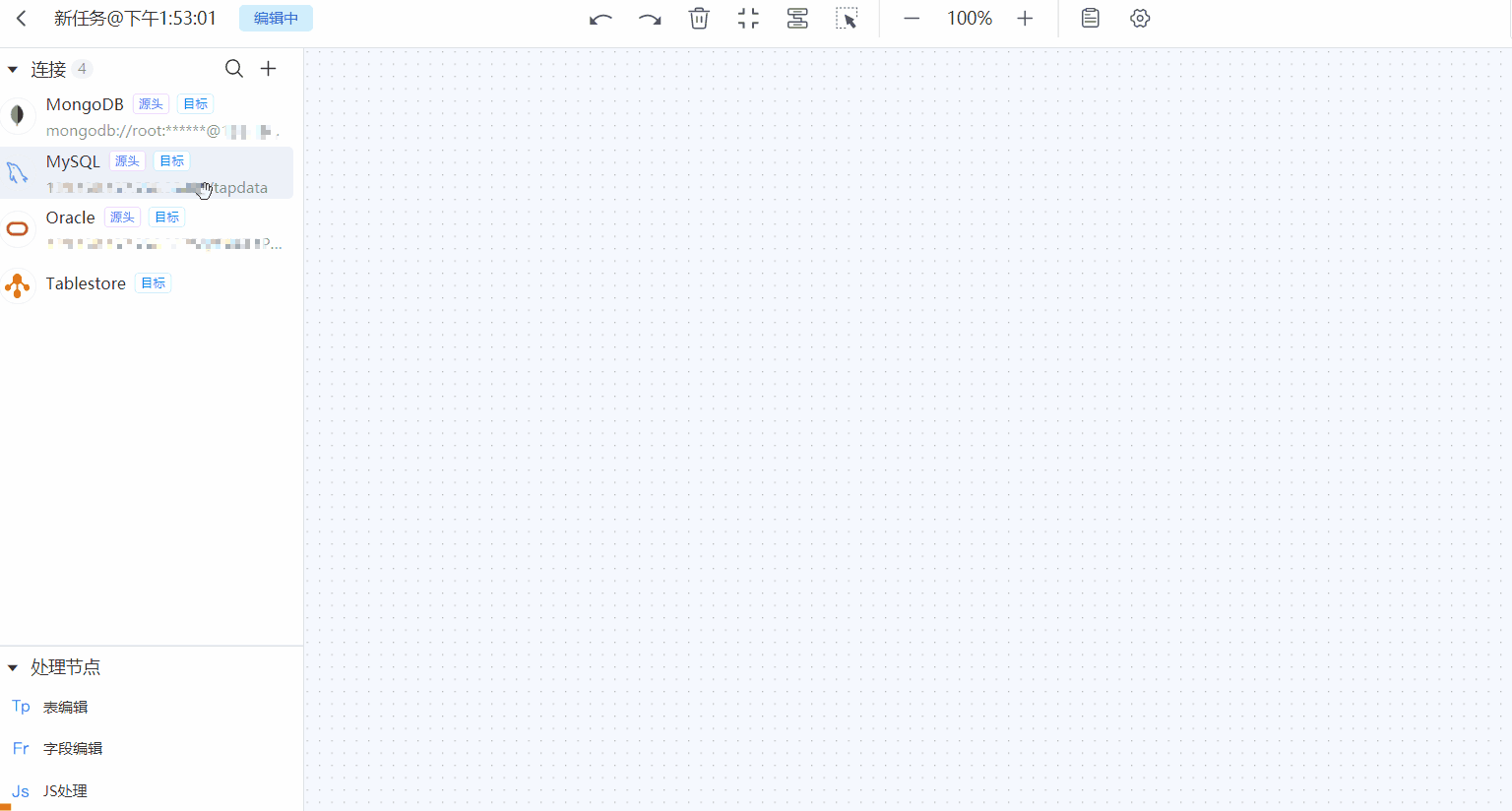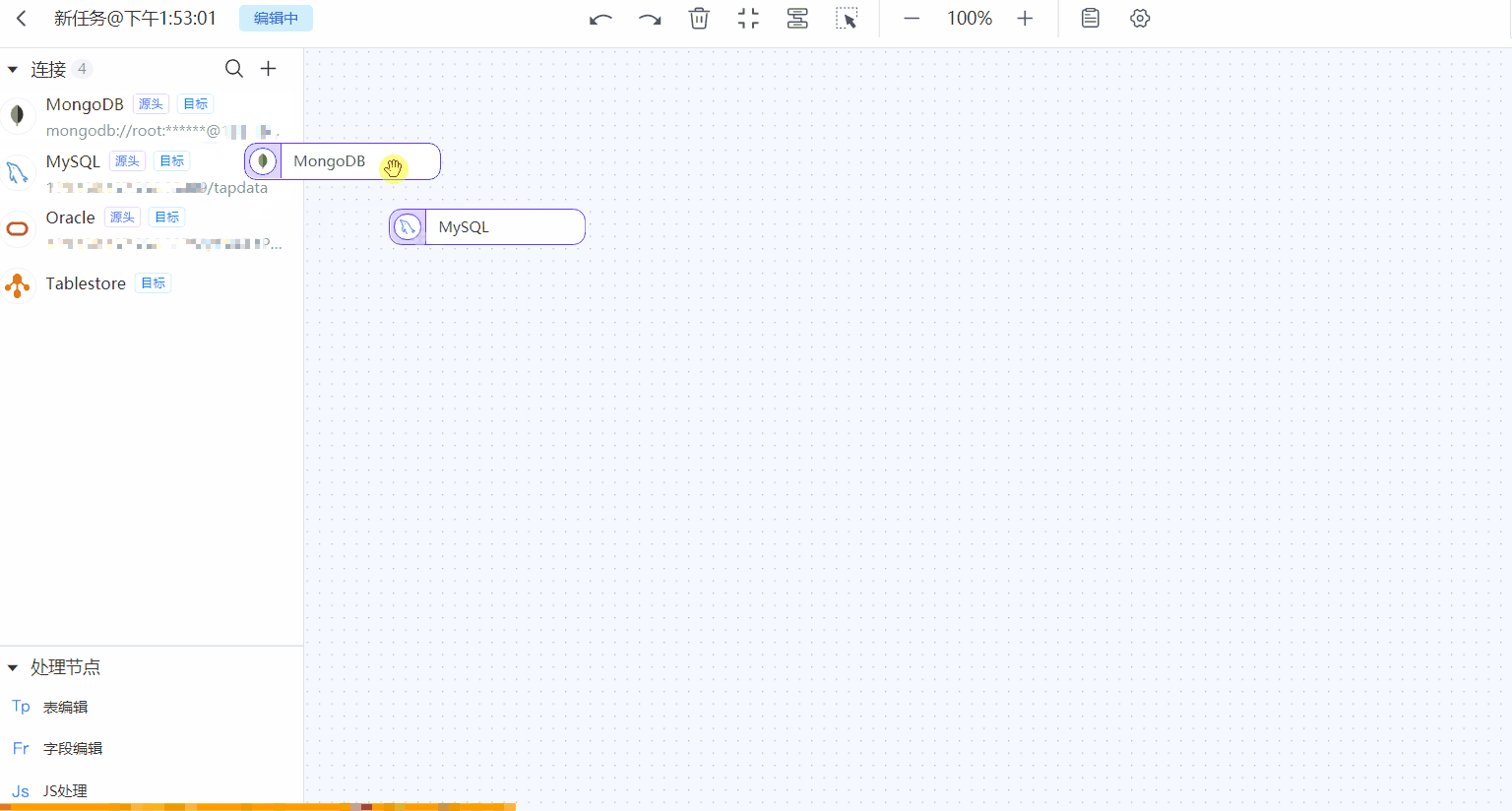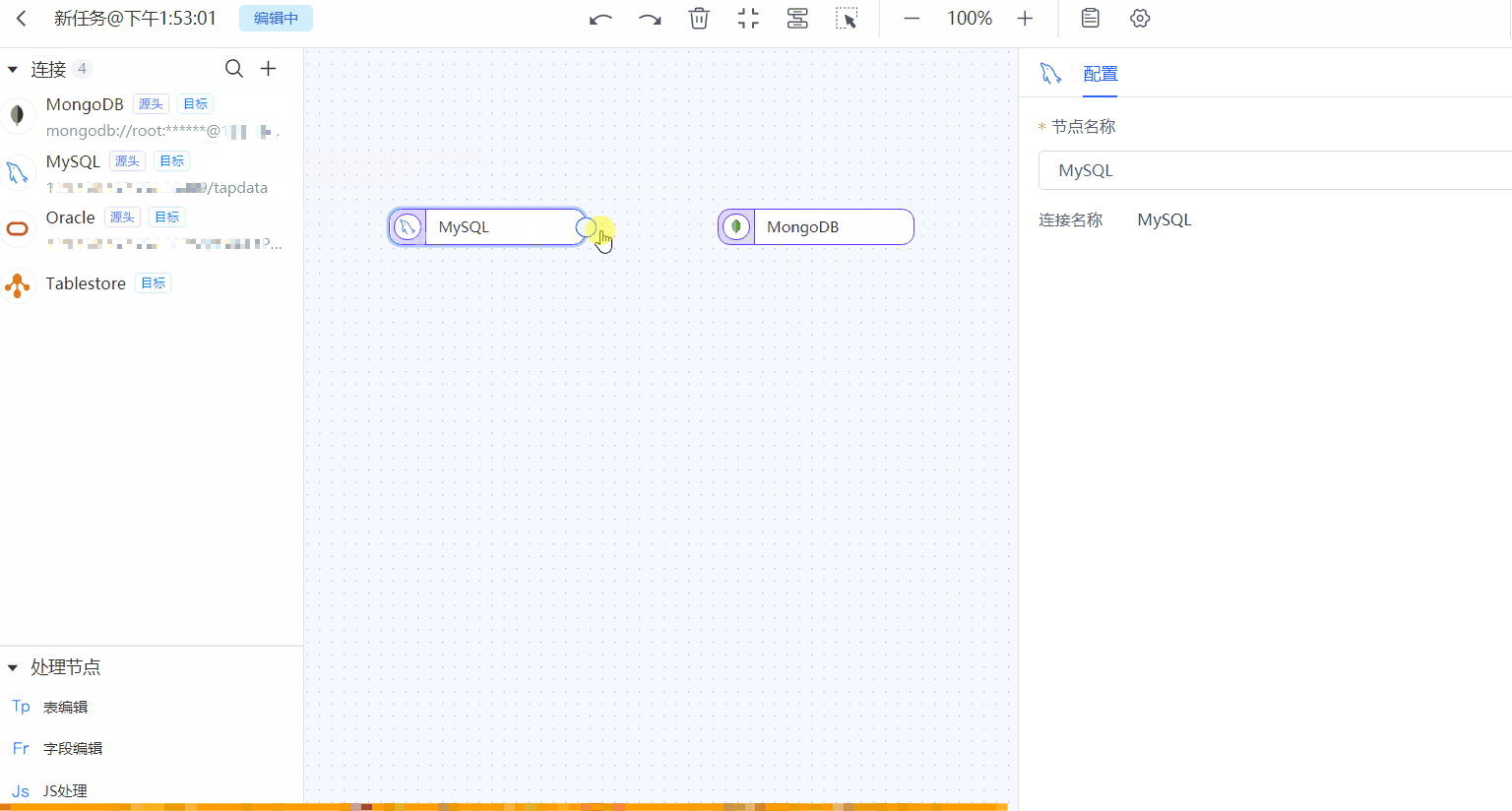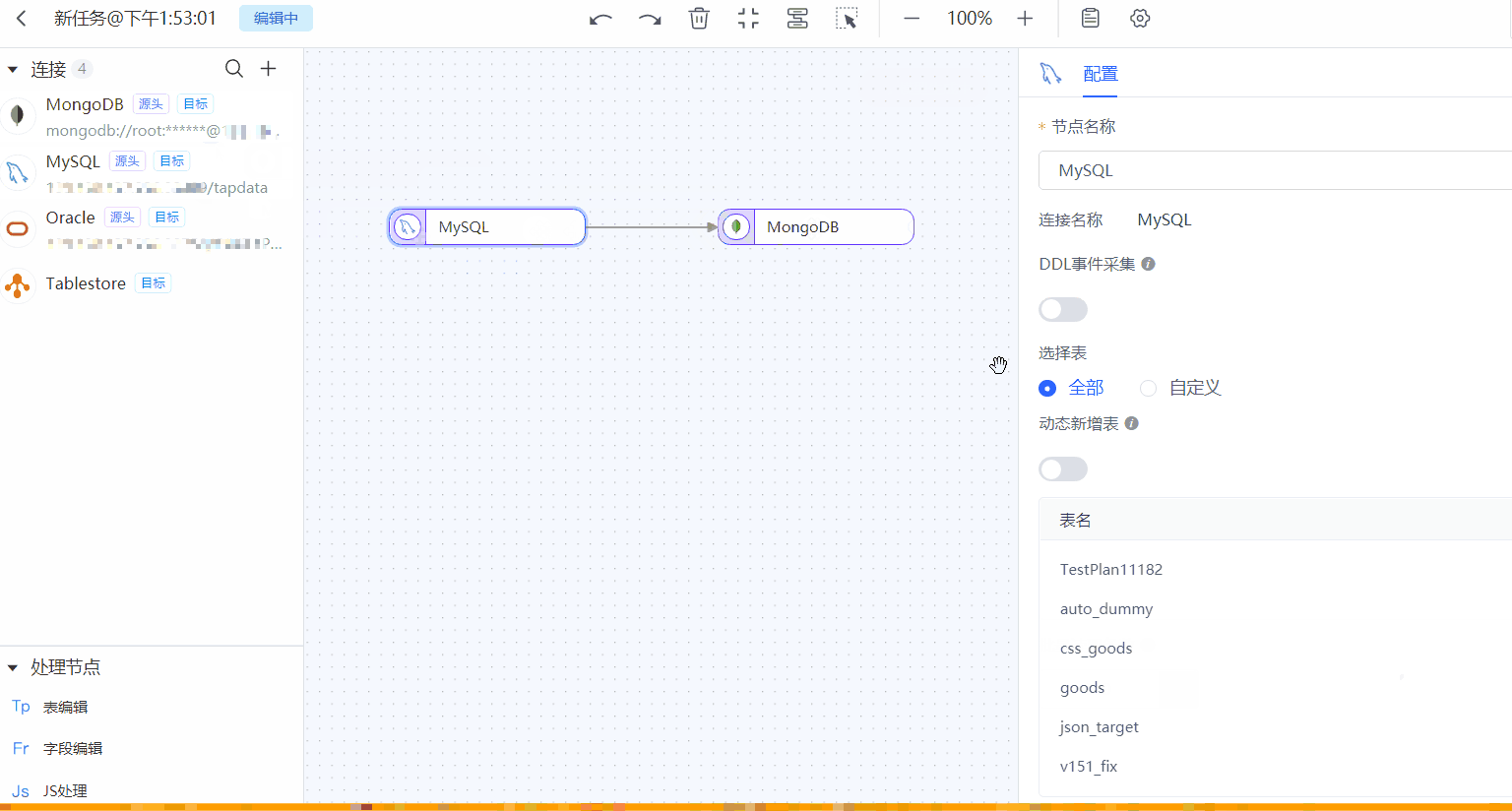
在页面左侧,分别拖拽作为源和目标的数据连接至右侧画布中,然后将二者连接。
 提示
提示除添加数据源节点外,您还可以添加处理节点以完成更复杂的任务,如过滤数据、增减字段等,更多介绍,见处理节点。
单击源端节点(本例为 MySQL),根据下述说明完成右侧面板的参数配置。
- 节点名称:默认为连接名称,您也可以设置一个具有业务意义的名称。
- DDL 事件采集:打开该开关后,Tapdata Cloud会自动采集所选的源端 DDL 事件(如新增字段),如果目标端支持 DDL 写入即可实现 DDL 语句的同步。
- 选择表:根据业务需求选择。
- 按表名选择:在待复制表区域框选中表,然后单击向右箭头完成设置。
- 按正则表达式匹配:填写表名的正则表达式即可,此外,当源库新增的表满足表达式时,该表也会被自动同步至目标库。
- 批量读取条数:全量同步时,每批次读取的记录条数,默认为 100。
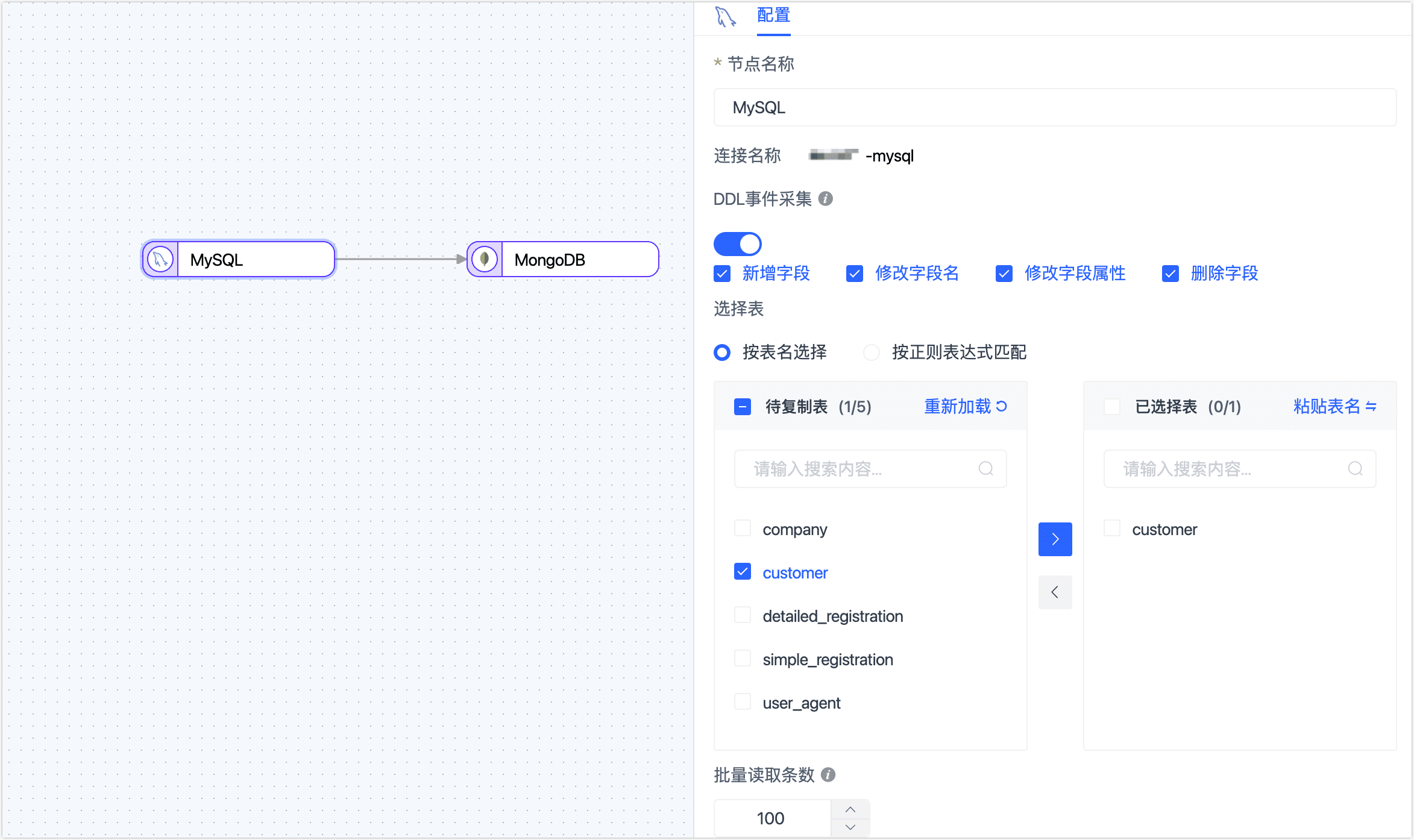
单击目标端节点(本例为 MongoDB),根据下述说明完成右侧面板的参数配置。
完成节点基础设置。
- 节点名称:默认为连接名称,您也可以设置一个具有业务意义的名称。
- 批量写入条数:全量同步时,每批次写入的条目数。
- 写入每批最大等待时间:根据目标库的性能和网络延迟评估,设置最大等待时间,单位为毫秒。
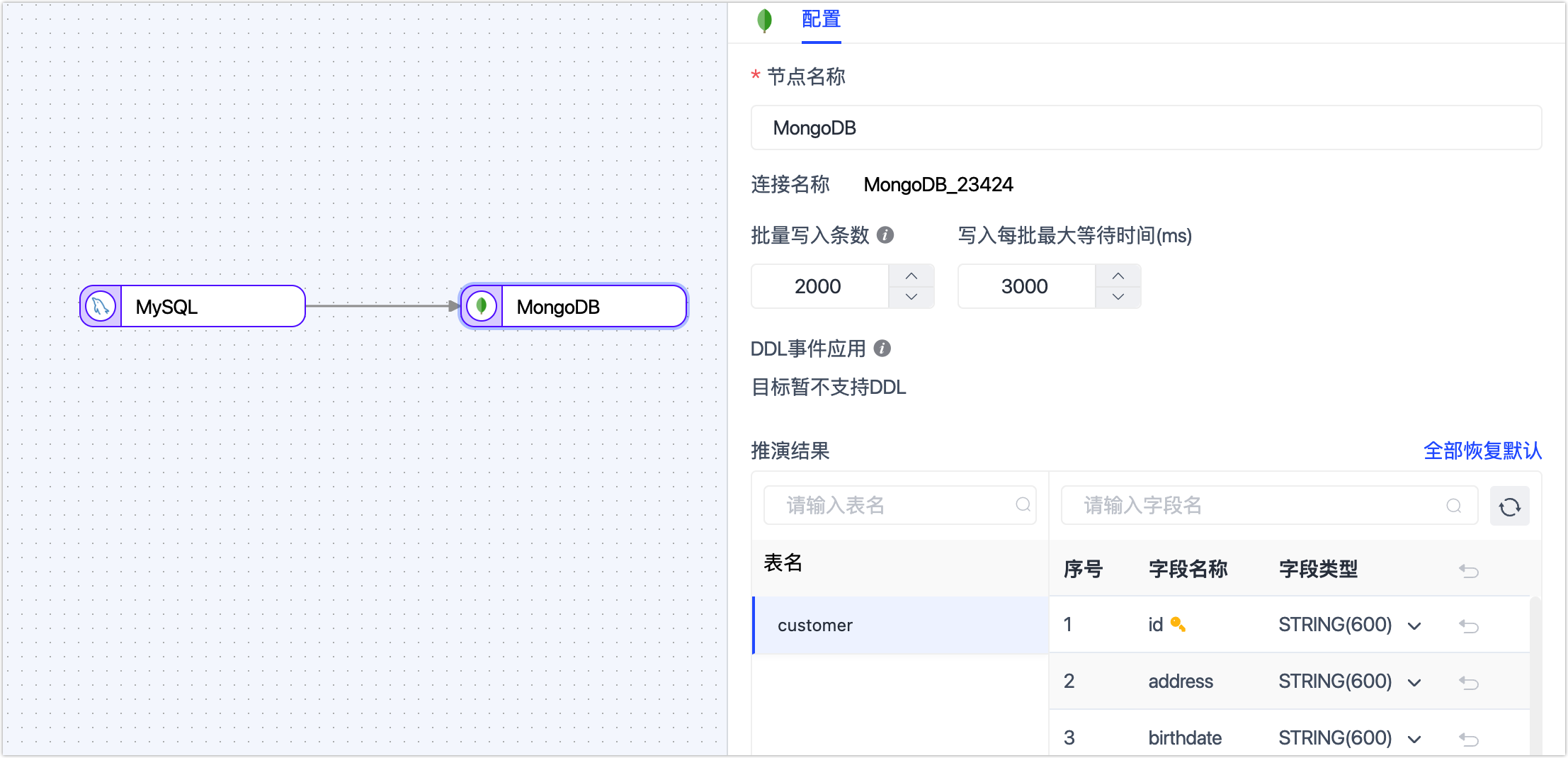
- 推演结果:展示 Tapdata 将写入目标端的表结构信息,该信息基于源端节点设置所推演。
下翻至高级设置区域框,完成高级设置。
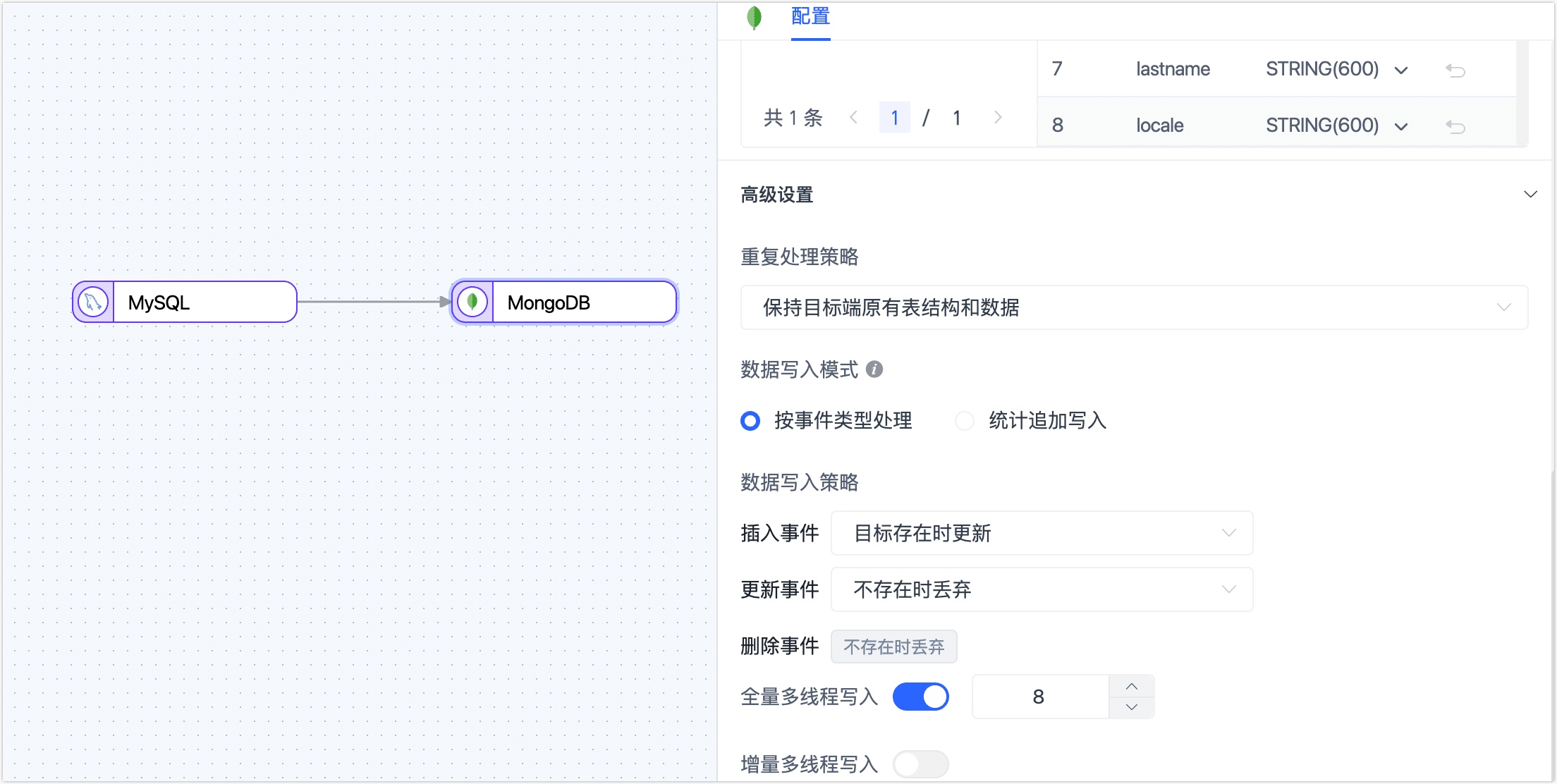
- 重复处理策略:根据业务需求选择,也可保持默认。
- 数据写入模式:根据业务需求选择。
- 按事件类型处理:选择插入、更新、删除事件的数据写入策略。
- 统计追加写入:只处理插入事件,丢弃更新和删除事件。
- 全量多线程写入:全量数据写入的并发线程数,默认为 8,可基于目标端写性能适当调整。
- 增量多线程写入:增量数据写入的并发线程数,默认未启用,启用后可基于目标端写性能适当调整。
(可选)单击上方的
 图标,配置任务属性。
图标,配置任务属性。- 任务名称:填写具有业务意义的名称。
- 同步类型:可选择全量+增量,也可单独选择全量或增量。 全量表示将源端的存量数据复制到目标端,增量表示将源端实时产生的新数据或数据变更复制到目标端,二者结合可用于实时数据同步场景。
- 任务描述:填写任务的描述信息。
- 高级设置:设置任务开始的时间、增量数据处理模式、处理器线程数、Agent 等。
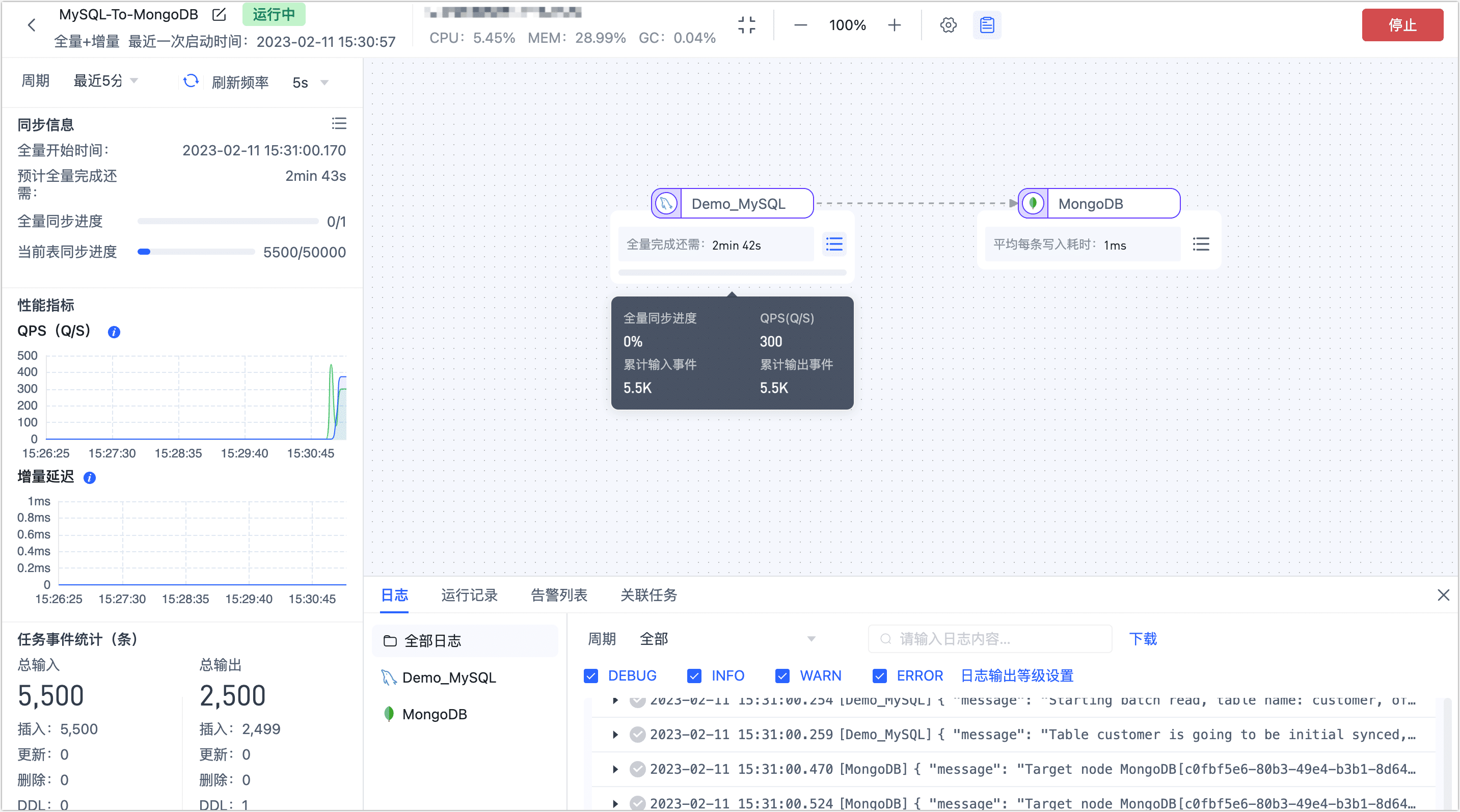
单击启动,操作完成后,您可以在当前页面查看到任务的执行情况,如 QPS、延迟、任务事件统计等信息。